컴퓨터 비전 분야에서 sfm (structure from motion) 은 많이 들어보셨겠죠.
이미지로부터 피쳐 추출 및 매칭, 대응점을 이용한 3차원 복원 기술 중에 하나입니다.
SLAM과 어떻게보면 비슷한 느낌이 있지만,
sfm은 (보통) 이미지에서 고려할 수 있는 모든 관계 (nC2)에 대한 피쳐 및 피쳐매칭을 수행하고,
이미지 사이의 관계 (포즈) 및, 대응점을 통한 3차원 복원을 수행합니다.
한 번 수행하는데 막대한 양의 시간이 소요되나, 꽤 정밀한 결과를 얻을 수 있죠.
특히나 제가 주로 연구하는 분야인, 딥러닝 기반의 카메라 자세 추정에서
이미지만으로 데이터셋을 라벨링 하기 위한 툴로 주로 사용됩니다. (이미지 -> 자세)
최근에는 더 발전된 형태의 Colmap이나 Meshroom등의 소프트웨어도 존재하는데
이 포스팅에서는 가장 오래된/널리쓰이는 sfm 툴인 VisualSFM에 대해 다루겠습니다.
위에서도 언급했듯이, SFM은 이미지를 넣으면, 그에 해당하는 각 이미지의 자세와 전체 이미지 대응쌍으로부터 획득한 3D모델들 제공해줍니다.
Visual SFM에서는 크게 3가지 단계로 진행하시면 됩니다.
1) 사전작업 (이미지 로드, 카메라 파라미터 설정, 매칭 설정 등)
2) 피쳐 추출 및 매칭 수행 -> 이미지의 자세 및 3D모델(점군) 획득
3) (필요시) 조밀한 점 군 획득 (Dense Reconstruction)
보통 1, 2만 수행해도 이미지의 라벨링은 완료되기에 큰 문제가 없습니다.
다만, 가시화나 정밀한 점 군을 획득하기 위해선 (3)의 과정이 필수적이며, 이를 위해선 VisualSFM 툴 설치 이후 추가적인 작업이 필요합니다.
직첩 어떤 특징점을 사용할지 선택할 수 있으나, 제가 직접 해보진 않았습니다.
당연하게도, 특징점 (VisualSFM 기본 > SIFT)을 활용하기에, 아무리 이미지를 많이 넣더라도, 특징점이 감지되기 어려운 환경에서는 원하는 결과를 얻을 수 없습니다 (Textureless, rapid motion change, blur 등)
VisualSFM + Dense Reconstruction 설치

우선 위 사이트에서 자신의 개발환경에 맞는 툴을 다운로드해줍니다.
CUDA설정을 완료하신 분이라면 CUDA 버전을 다운로드합니다.
(*CUDA설치가 되어있어야 하는지는 모르겠으나, CUDA버전과 아닌 것, 속도차이가 꽤 나니 참고.)
Dense Reconstruction을 위해 저자가 링크를 몇 개 걸어두었는데, 현재는 위쪽의 링크는 모두 막힌 상태입니다.
대신 Download에 있는 Installation guide를 클릭합니다.
그러면 이렇게 다른 링크를 제공합니다. Furukawa's CMVS software가 Dense Reconstruction을 위한 추가 파일들을 포함하고 있습니다.

링크를 계속 타고가면,
결국에는
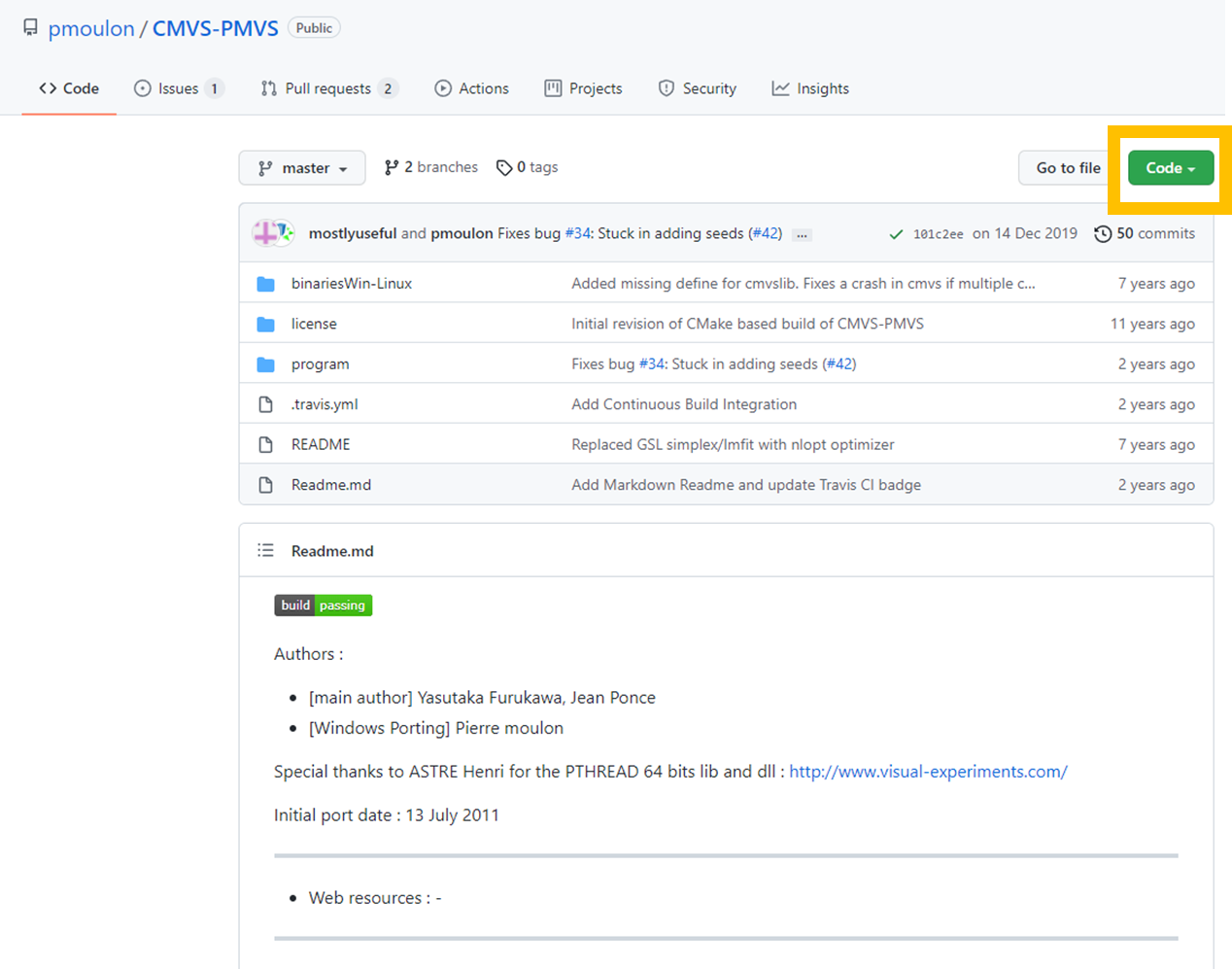
이 깃허브 페이지에 도착하게 됩니다.
다운로드 이후
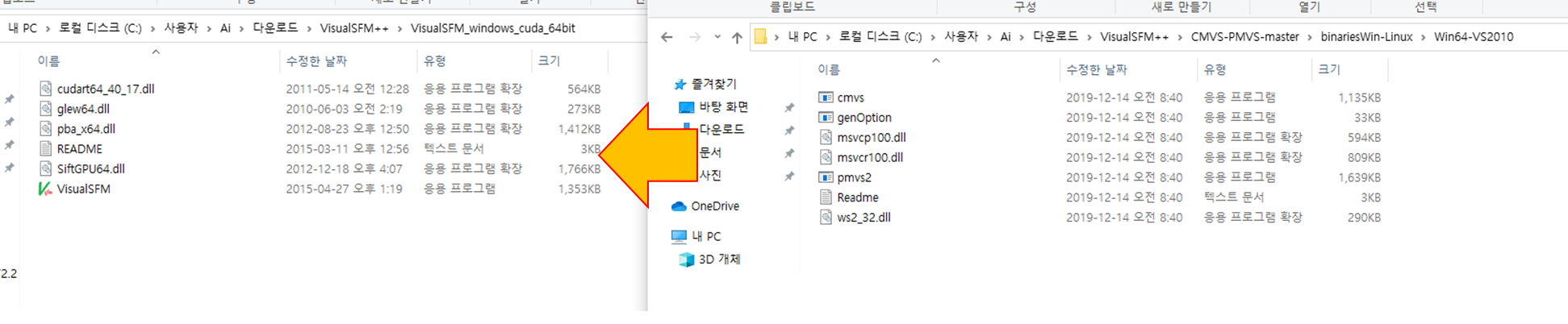
VisualSFM을 다운로드 받은 폴더 내에, CMVS폴더 내의 Win64-VS2010의 파일들을 모두 넣어줍니다.
(혹시나 추후 VS관련 오류가 난다면 VS를 설치해주거나, 재배포 패키지를 설치합니다. VisualSFM의 링크는 막혀있으니 주의)
VisualSFM 실행
저는 기본적으로, VisualSFM으로
입력 : 이미지, 카메라 파라미터
출력 : 이미지에 해당하는 자세, 3D모델(Dense)
를 획득하도록 실행합니다.
이들의 활용도는
1) 딥러닝 기반 카메라 자세 추정 (이미지로부터)
2) 자세추정 결과 가시화 (증강현실 : 3D모델을 이미지에 해당 자세로 증강)
입니다.
우선 이미지를 로드해줍니다.
임의의 이미지들을 로드해줍니다. 귀여운 네즈코로 데이터셋을 한번 만들어봤는데,
이 포스팅을 보는 분들이라면 당연히 아시겠지만, 이미지와 이미지 사이에 공유하는 피쳐가 반드시 존재해야 합니다.
보통 비디오영상 -> 연속되는 이미지 다수 로 변환하실텐데, 설령 sfm이 Pairwise 매칭이 아닌, 전체 이미지에 대한 모든 쌍을 고려하는 알고리즘이라지만, 그래도 공유하는 피쳐가 존재하는게 좋겠죠. (설정으로 Pairwise하게 매칭하도록 할 수 있습니다)
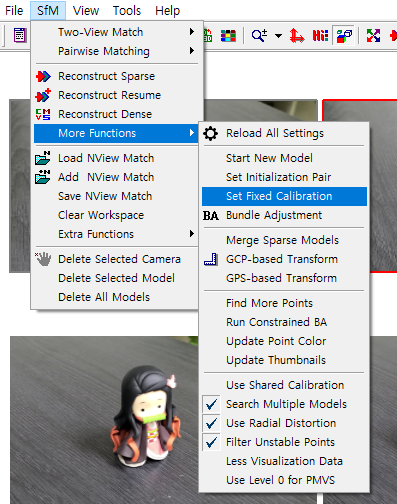

이후 메뉴 > SfM > More Functions > Set Fixed Calibration에서 카메라 파라미터를 입력해줍니다.
이 부분을 지정해주지 않으면 SfM에서 임의로 카메라 내부 파라미터를 추정하게 됩니다.
(논문/코드를 안봐서 어떤 알고리즘인지는 모르겠음)
저는 당연히 제가 사용하는 카메라의 카메라 내부 파라미터를 알기에 굳이 그럴 이유가 없어, 제 파라미터를 입력하빈다.
순서는 fx cx fy cy r 순서입니다만, r은 생략가능해서 4개의 파라미터를 순차적으로 입력해주면 됩니다.
[중간에 콤마가 없습니다. 스페이스입니다]
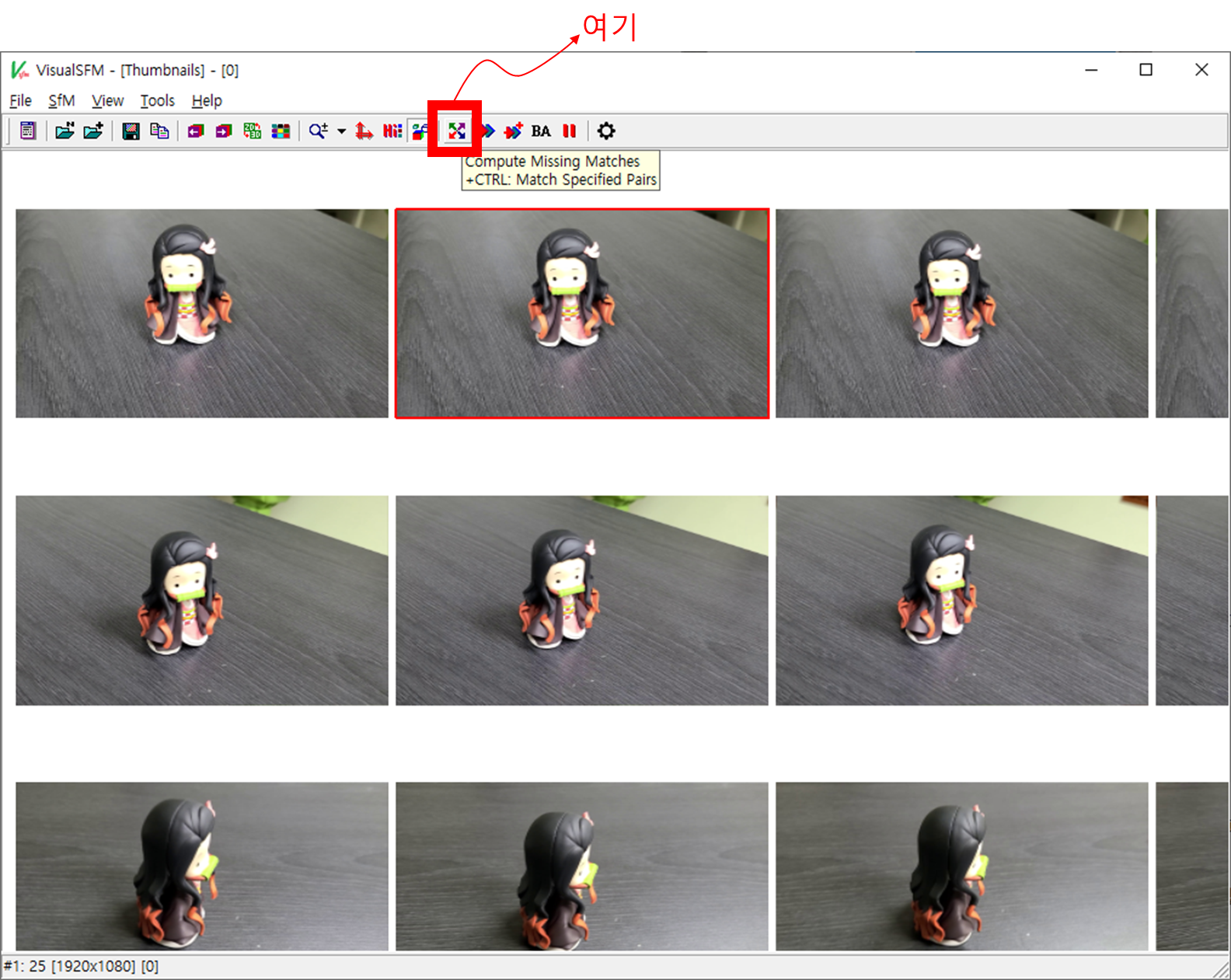
이후엔 위의 "Compute Missing Matches"를 수행합니다.
이미지에서 피쳐(SIFT)를 추출합니다.
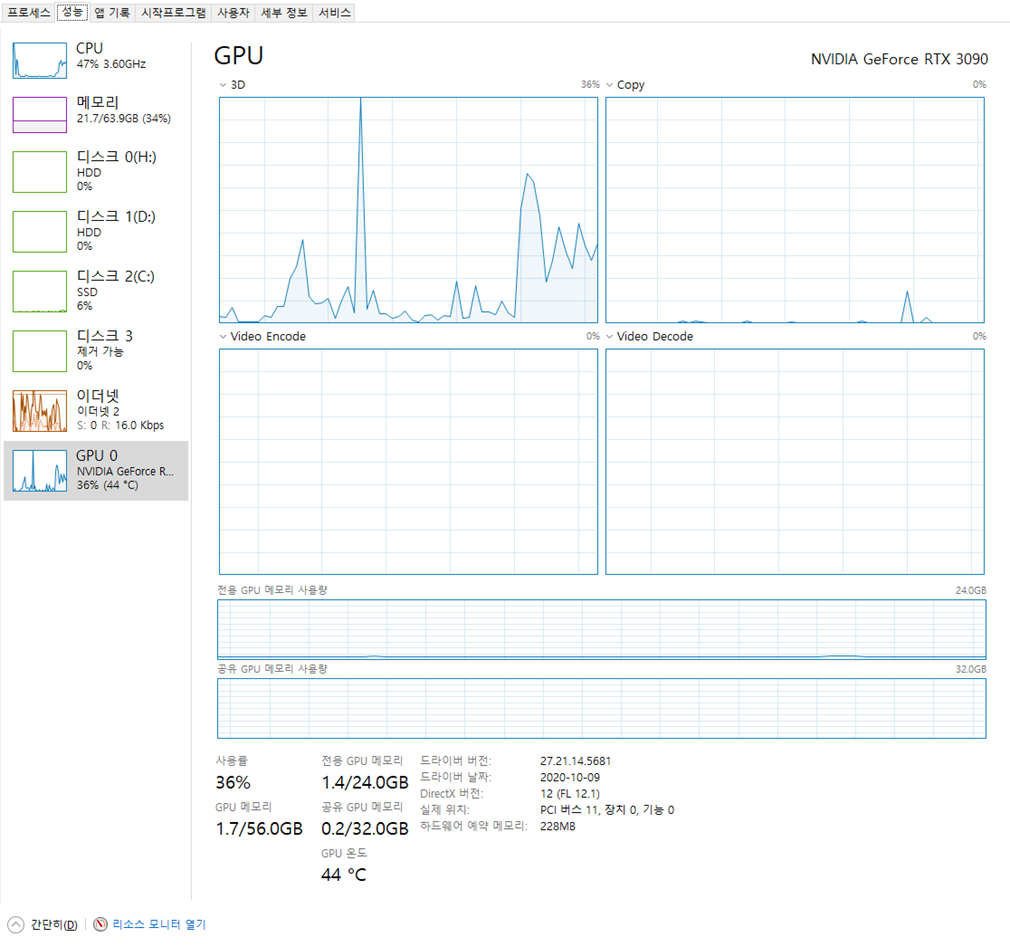

RTX 3090 기준 66장의 이미지처리가 23초만에 완료되었습니다. 일부 GPU를 활용하는 것 같네요.
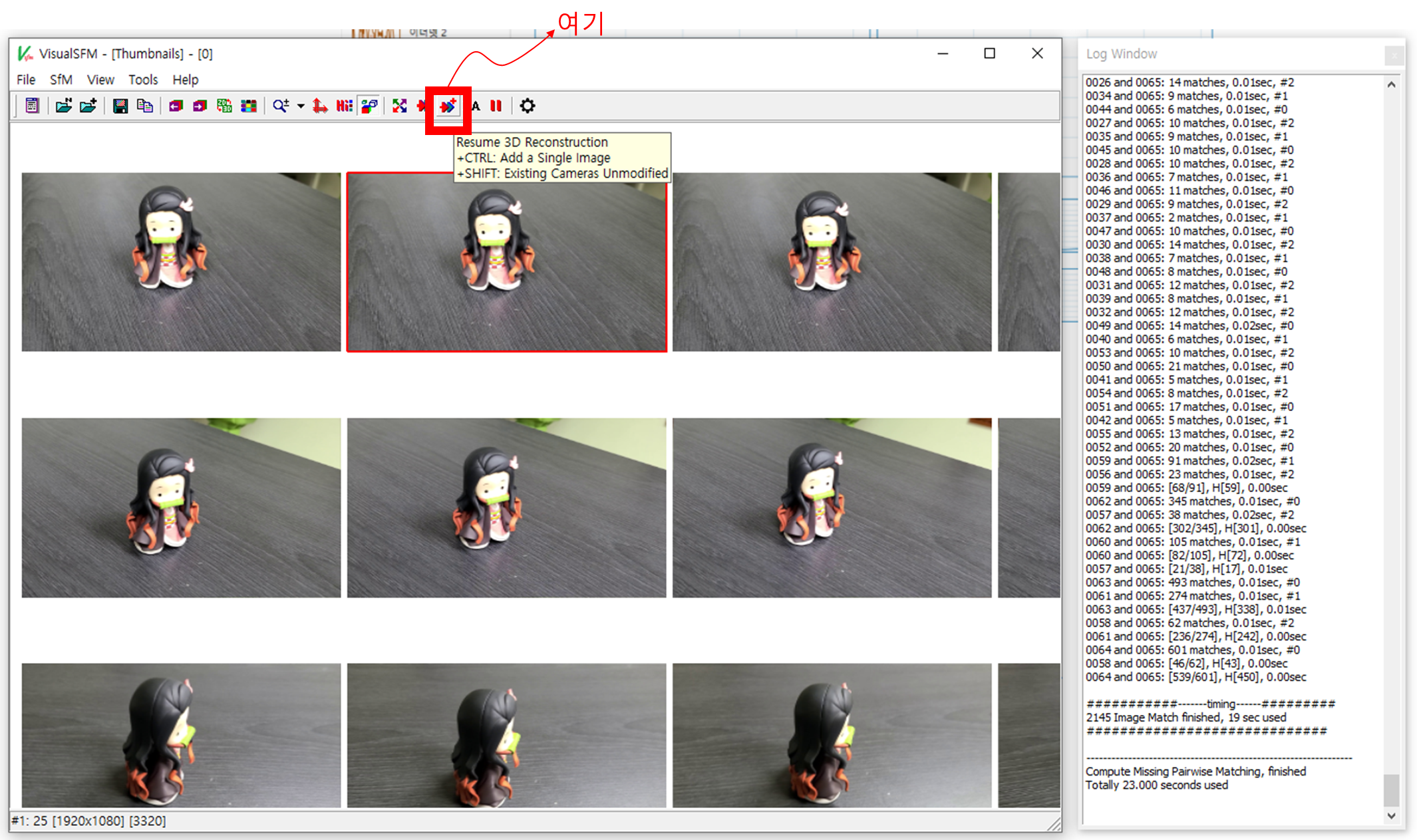
이후에 Reconstruction을 수행합니다. 처음에는 Sparse reconstruction만 가능합니다.

작업이 완료되면 복원된 점 군과, 각 이미지의 자세가 가시화됩니다. 14초가 걸렸네요.
(이 때는 멀티쓰레드와 GPU를 그다지 활용하지 않는 것으로 보입니다. 둘다 점유율이 낮아요)
(CUDA버전을 쓰지 않았을때 80초가량 소요되었음)

만약 여기까지 (Sparsely reconstructed point cloud + poses of images) 만의 결과로도 충분하다면,
메뉴에서 현재의 내용을 저장합니다.
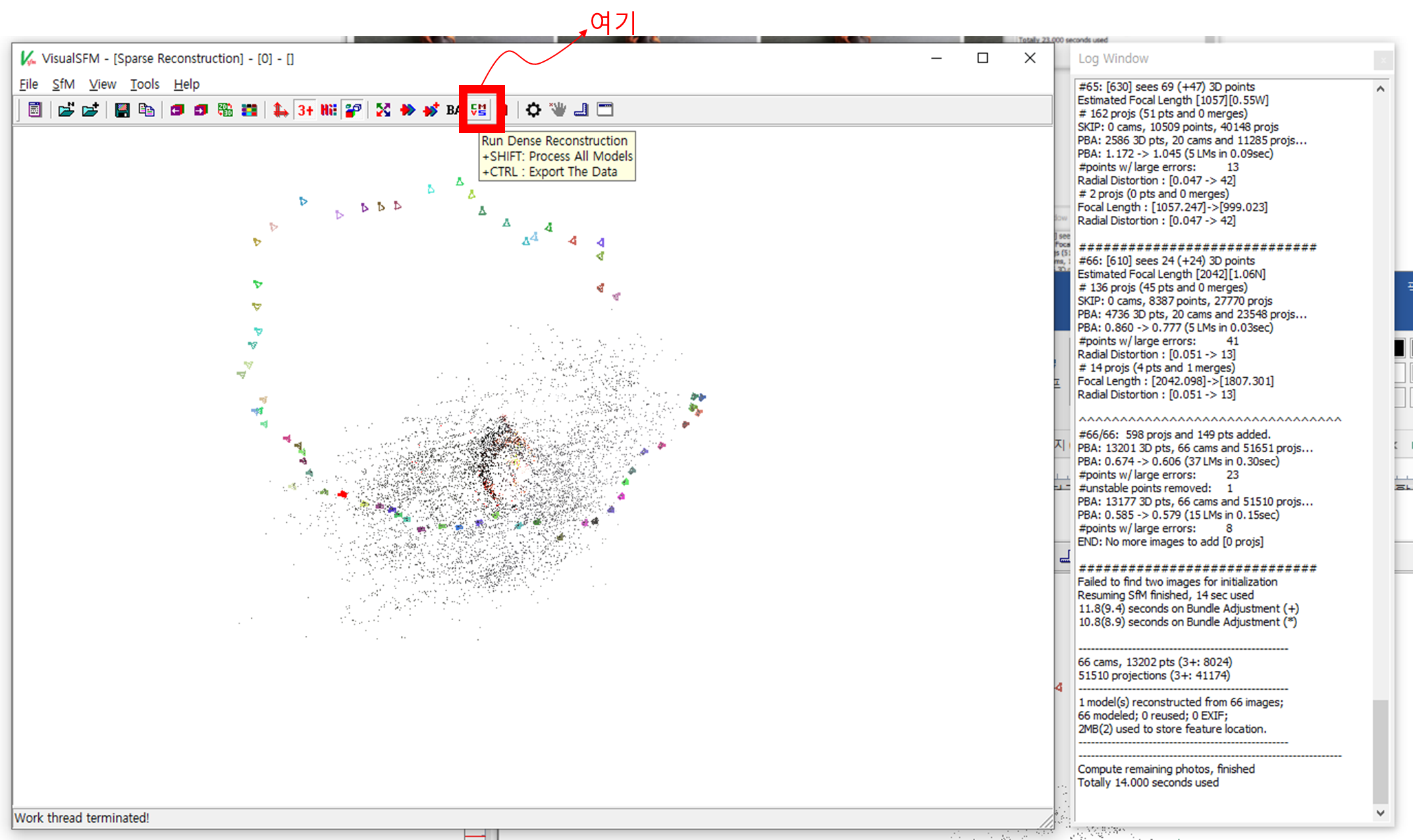
Spare Reconstruction이 수행되고 나면, Dense Reconstruction 메뉴가 생성됩니다.
좀 더 정밀하게 복원된 점 군을 획득하고 싶다면, Dense Reconstruction을 수행합니다.
* 저는 이를 Dense라는 이름으로 저장하도록 하였습니다.
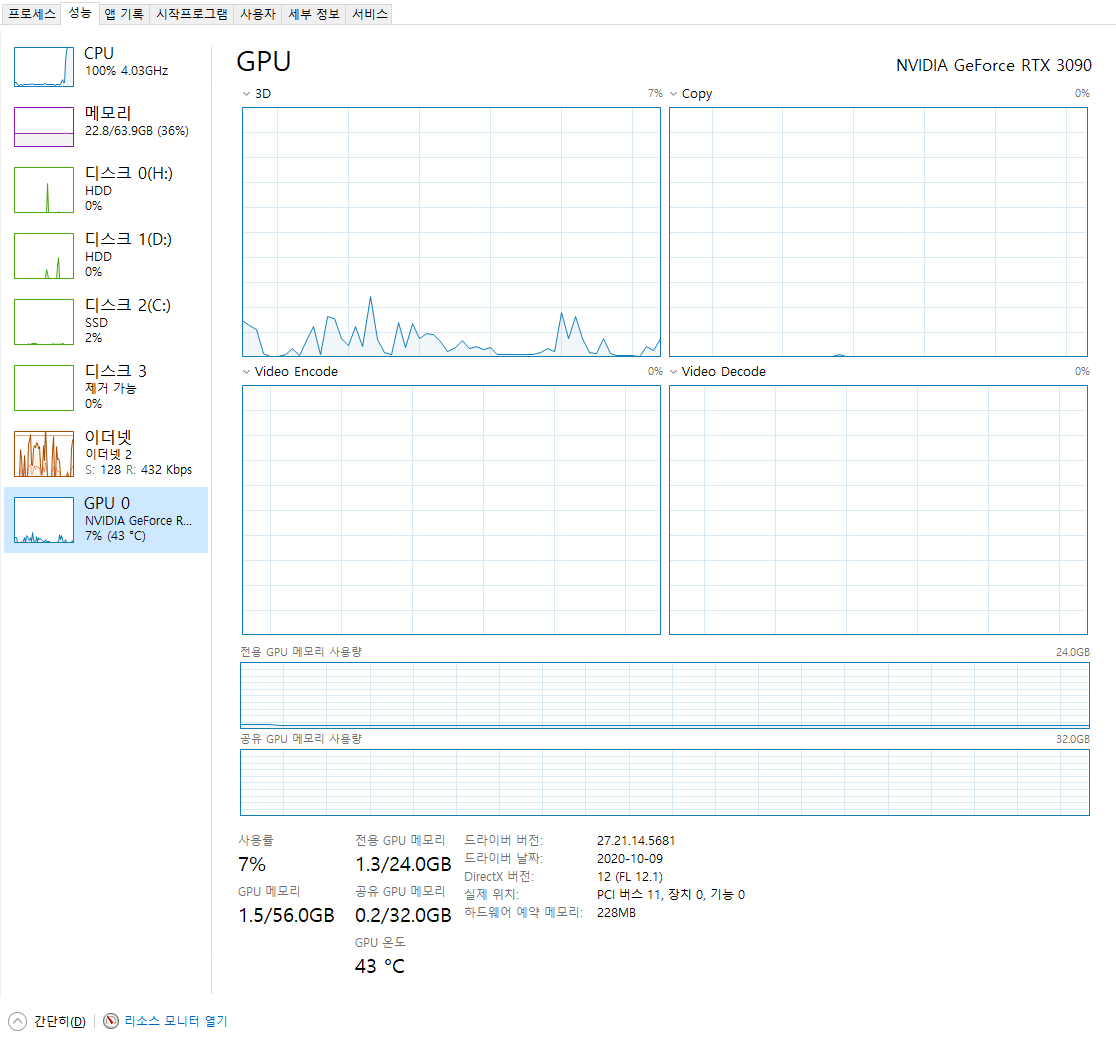
제 설정 미스인지, 이 때는 CPU만을 활용하더라구요.

66장의 이미지 기준 35초가 소요되었습니다. (모델 뷰어 화면에서 탭키를 누르면 Sparse - Dense 점군 가시화가 전환됩니다.
여기까지 따라하셨다면,

Sparse.nvm, Dense.nvm, Dense.0.ply 와 함께
Dense.nvm.cmvs 폴더가 생성됩니다.
사실상 Sparse.nvm = Dense.nvm이며,
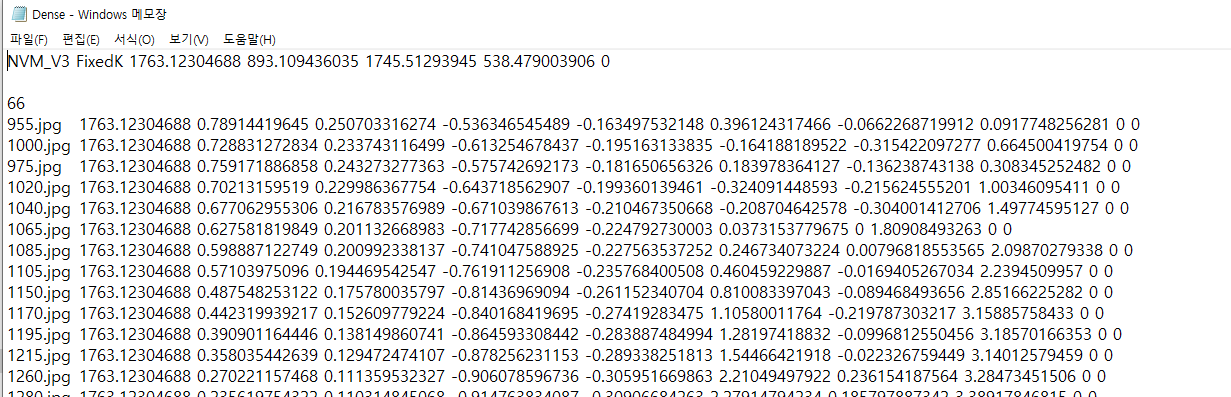
nvm파일은 이렇게 저장됩니다.
만약 Fixed calibration을 설정하지 않았다면,
맨 첫줄에 카메라 파라미터가 적혀있지 않습니다.
아래의 이미지 이름과 숫자들의 Specification은 홈페이지에 상세하게 잘 기록되어 있습니다.
문서의 상단부에는
[이미지 이름 f qw qx qy qz x y z ... ] 형태로 저장되어있습니다.
서실상 저희가 필요한 건, 이미지와 이미지에 해당하는 자세이기 때문에 원하는 정보는 모두 기록되어 있는 것이죠.


Dense.0.ply 파일을 열어보면, 원하는대로 잘 저장된 모습입니다.
요약하면,
카메라 내부 파라미터 => 캘리브레이션으로 사전에 알고 있음
.nvm => 이미지와 이미지에 해당하는 자세 추출
.ply => 점 군
을 뽑아낼 수 있습니다.
.ply파일의 점 군을 .nvm에서 가져온 이미지 자세로(Camera extrinsic matrix) 이미지위에 카메라 내부 파라미터 (Camera instrinsic matrix)로 투영한다면 (Projection matrix) 이미지 위에 .ply의 점군이 정확하게 증강됩니다.
주의점
* 한 가지 주의할 점은, nvm에 적힌 x, y, z입니다.
Dense Reconstruction을 수행하면, 점 군 이외에 매우 상세한 내용들까지 기로되는데요, Dense.nvm.cmvs폴더를 참고합니다.
Dense.nvm.cmvs/00/centers-all.ply 파일에는 카메라의 위치가 저장됩니다.

가시화하면 이런식으로 볼 수 있습니다.
또한
Dense.nvm.cmvs/00/cameras_v2.txt 파일에는 각종 상세한 내용이 기록됩니다.

# Filename (of the undistorted image in visualize folder)
# Original filename
# Focal Length (of the undistorted image)
# 2-vec Principal Point (image center)
# 3-vec Translation T (as in P = K[R T])
# 3-vec Camera Position C (as in P = K[R -RC])
# 3-vec Axis Angle format of R
# 4-vec Quaternion format of R
# 3x3 Matrix format of R
# [Normalized radial distortion] = [radial distortion] * [focal length]^2
# 3-vec Lat/Lng/Alt from EXIF
이런 형태로 각 이미지에 대한 상세한 내용이 기록되는데,
위에서 작성한 대로, 약간 주의할 점이 있습니다.
.nvm에 기록된 x, y, z는 이 .txt파일에서의 3-vec Camera Position C (as in P=K[R-RC]) 에 해당합니다.
이 Camera position 대신 3-vec Translation T (as in P = K[R T]) 를 사용하는 것이, 보다 일반적인 경우라고 생각됩니다.
(모델을 이미지에 K, R, T로 증강시키는 경우)
저는 자체적으로 .nvm파일의 C를 T로 변환하는 코드 + .nvm파일 내의 {이미지, 자세} 리스트를 natural keys로 sorting해서 저장하도록 하고있습니다 (0, 1, 2, 3, 4, 5, .. 순으로 저장하도록)
댓글